Bezpieczne dane na S3 to jeden z istotniejszych aspektów jeśli chodzi o przechowywanie danych w chmurze.
Temat ten omawiany wielokrotnie, a mimo to nadal wzbudza pewne wątpliwości. Wiele razy można było usłyszeć o różnych sytuacja „wycieku danych z chmurze”. Oczywiście te „lotne” tytuły miały na celu przyciągnąć czytelników.
Na koniec i tak sprowdzało się zazwyczaj to tego, że ktoś w wyniku braku odpowiedniej wiedzy czy kompetencji upubliczniał dane w sposób niekontrolowany i niekoniecznie świadomy.
Dla wyjaśnienia, warto wspomnieć, że domyślnie każdy bucket S3 i każde umieszczone w nim dane są prywatne.
Jak widać, jednak to nie uchroniło kilka firm przed kompromitacją związaną z upublicznieniem wrażliwych danych.
Co w takim razie można zrobić?
Kontrola dostępu do danych na S3
Zanim przejdziemy do tego w jaki sposób zabezpieczyć swoje dane przed publikacją, przyjrzyjmy się jakie mechanizmy kontroli dostepu oferuje usługa Amazon S3.
W tej części artykułu poznamy jak działają te mechanizmy i jak je konfigurować.
Czym jest Amazon S3
Słowem jeszcze wprowadzenia, usługa Amazon S3 jest rozwiązaniem typu „object storage”, która pozawala użytkownikom przechowywać dane dowolnego typu w dowolnej ilości. Dane składowane są w tzw. bucket’ach.
Usługa oferuje obecnie masę funckjonalności jak wersjonowanie, website static hosting i inne. Więcej możesz się dowiedzieć na ten temat z mojego ebooka.

W skrócie, chcąc przechowywać dane w usłudze S3, należy stworzyć bucket i zaczać ładować do niego dane.
Kto ma dostęp do danych na S3?
Tak jak wspomniałem już wcześniej, domyślnie zarówno bucket jak i dane w nim umieszczone są prywatne. Przez prywatne rozumiem, tutaj, że dostęp do nich mają jedynie użytkownicy konta AWS, na którym buckety i dane zostały stworzone/umieszczone. Oczywiście jest to prawdą, jeżeli uprawnienia użytkownika nie ograniczają mu dostępu do S3.
Spójrzmy zatem na dwa główne mechanizmy kontrol uprawnień jakie dostępne po stronie usługi Amazon S3.
ACCESS CONTROL LIST (ACL)
Access Control List, w skrócie ACL to pierwsza z możliwości. ACL może być zdefiniowana na poziome samego bucketu.
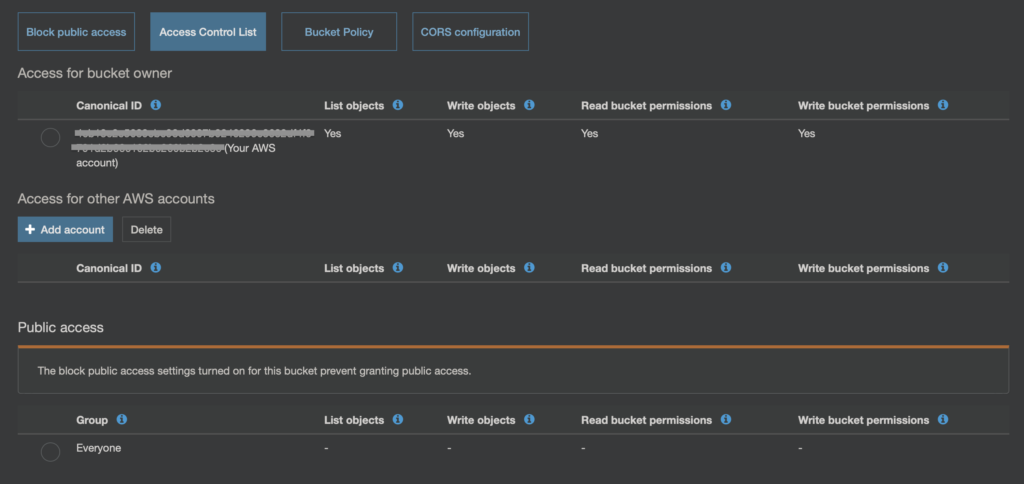
Jak widać na powyższym obrazku, ACL pozwala np. na określnie dostępu dla innego konta AWS (Access for another AWS Account), lub też definiuje uprawnienia dla Everyone, czyli dla całego świata (Public Access).
To jest właśnie jedno z miejsc, w którym można „niechcący” pozwolić na dostęp do danych. W tym wypadku bardziej do listowawani całej zawartości bucketu (List objects).
Stanie się to w momencie gdy dla Everyone zezwolimy na operację „List objects”.
Zagrożenie jest w tym momencie takie, że dysponując listą tego co jest w bucket’cie można próbówac po kolei odwoływać się do każdego z elementów. Jeśli, któryś z nich ma uprawnienia pozwalające na dostęp publiczny, no to mamy potencjalny wyciek danych.
ACL-ki można rownież definiować na poziomie samych obiektów (plików), który umieścimy w bucket’cie S3.
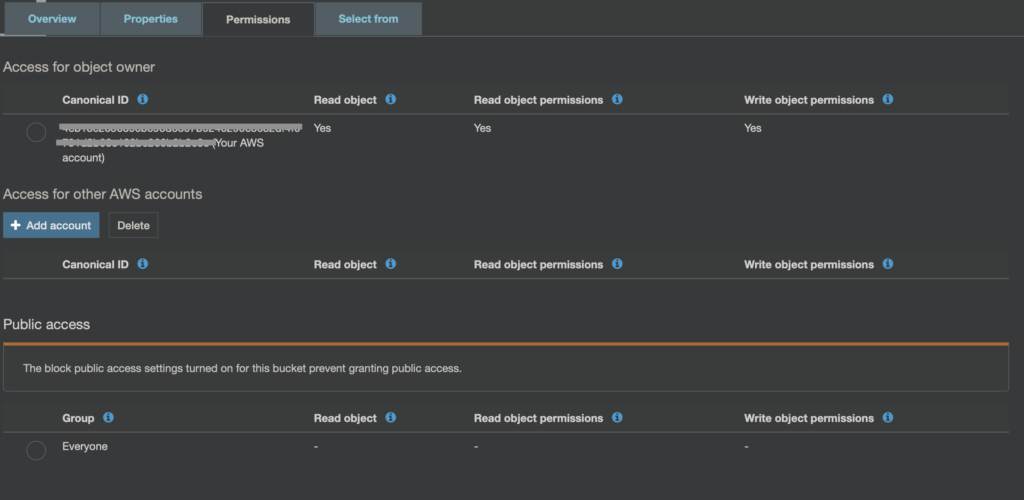
Jak widać na obrazku powyżej, parametry ACL dla obiektu bardzo zbliżone są do tych jak dla bucket’u. Warto tutaj zwrócić uwagę, że tak właśnie wygląda ACL, dla domyślnie wrzuconego pliku.
Domyślnie plik jest prywatny, a próba wywołania jego URL zakończy się komunikatem o braku dostępu.
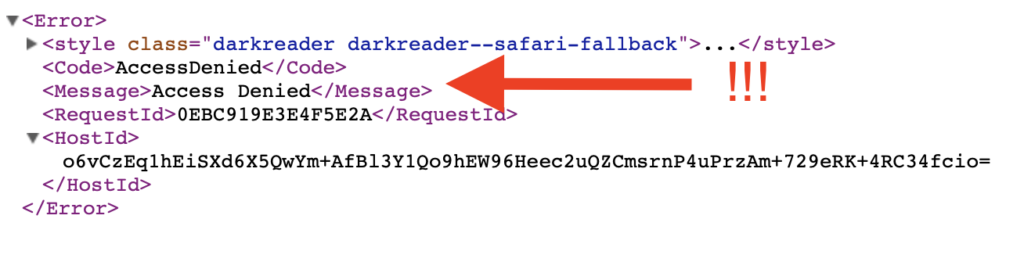
Przyjrzyjmy się jeszcze raz parametrowi Everyone. W przypadku objektu, tym co jest zagrożeniem jeśli chodzi o upublicznienie, to włącznie Read object dla Everyone.

Gdy tylko spróbujemy zaznaczyć „Read object”, pojawi się ostrzeżenie, że dany objekt będzie publicznie dostępny.
Teraz po zapisaniu ustawień i ponownym wywołaniu URL (https://lukado-bucket.s3-eu-west-1.amazonaws.com/index.html) do tego obiektu, dostaniemy jego zawartość.

Największe zagrożenie związane z S3 ACL’s
Nie wiem czy udało Ci się zauważyć, ale w ACL na poziomie bucketu, nie zmieniałem żadnej konfiguracji jeśli chodzi o Everyone.
Z kolei przed chwilą zmieniłem te ustawienia jeśli chodzi o obiekt (plik index.html), któremu nadałem publiczne uprawnienia.
Co to oznacza?
Że każdy object, może mieć własne ustawienia Access Contro List. Nie widać też tego z poziomu konsoli w sposób prosty, który z obiektów jakie ma ustawienia w ACL.
Popatrz na liste poniżej.

To jest widok z konsoli AWS na zawartość mojego bucket’u S3. Nie widać jest niestety, które z tych plików są lub nie są dostępne publicznie. W moim przypadku tylko index.html ma ustawione „Read object” dla Everyone, ale z tego widoku to nie wynika.
Dlatego właśnie to jest coś, co nie tak łatwo wyłapać z widoku konsoli i trzeba na to uważać.
Jak sobie z tym radzić, omówimy w drugiej części artykułu.
Bucket Policy
Drugim mechanizmem kontroli dostępu do danych na S3 są tzw. Bucket Policy.
W przeciwieństwie do ACL, Bucket Policy definiowana jest na poziomie bucket’u S3 i wszystkie elementy, które są w nim umieszczone dziedziczą te uprawnienia. Dlatego też jest to dużo „jaśniejszy” sposób kontroli uprawnień do danych.
Bucket Policy mają zastosowanie w różnych sytuacja. Pierwszą z nich może być właśnie potrzeba tego aby wszystkie dane które umieścimy w S3 były publiczne (świadomie ?).
Dla przykładu potrzebujemy serwować jakiś statyczny kontent dla użytkowników, S3 świetnie się do tego sprawdza (website static hosting).
Zatem, w takiej sytuacji aby zapewnić, że wszystkie elementy, które umieszczone są w buckecie były publiczne, należy stworzyć odpowiednią bucket policy.
Poniżej przykład takiej polityki:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-public-bucket/*"
}
]
}Warto zwrócić uwagę, że tutaj po zastosowaniu takiej polityki natychmiast pojawi się informacja, o tym, że bucket i jego zawartość jest publicznie dostępna.
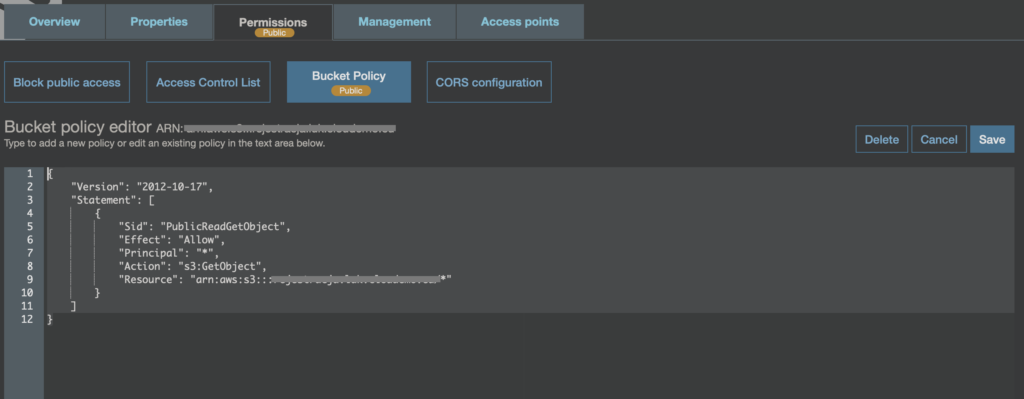
Zatem w tym wypadku o wiele łatwiej zauważyć, że pewne dane są publicznie dostępne.
Oczywiście Bucket Policy nie służą wyłacznie udostępnianiu publicznie danych. Za ich pomoca można granuralnie określić kto i na jakich zasadach ma dostęp do danych w buckecie.
Można nadawać dostęp do bucket’u innym usługom lub kontom AWS. Jednym z takich przypadków, może być np. określnie uprawnień do zapisywania logów z ruchu sieciowego, tzw. VPC Flow Logs.
Poniżej przykład takiej polityki
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "AWSLogDeliveryWrite",
"Effect": "Allow",
"Principal": {
"Service": "delivery.logs.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-flow-logs-bucket/flow-logs/AWSLogs/111111111111/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
},
{
"Sid": "AWSLogDeliveryAclCheck",
"Effect": "Allow",
"Principal": {
"Service": "delivery.logs.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::my-flow-logs-bucket"
}
]
}Teraz polityka jest zdecydowanie bardziej rozbudowana.
Określone jest dokładnie KOMU (Principal) nadane są uprawnienia – w tym wypadku usłudze odpowiedzialnej za dostarczanie logów.
Do jakich zasobów (Resource), czyli konkretny bucket S3. Oraz jakie operacje (Action) są dozwolone w ramach tego zasoby – tutaj s3:PutObject i s3:GetBucketAcl.
PODSUMOWANIE CZĘŚĆ 1
Amazon S3 oferuje dwa podstawowe mechnizmy określania uprawnień do danych:
- Access Control List – definiowane niezależnie dla bucketów jak i poszczególnych obiektów. Trudniej zarządzalne oraz mniej przejrzyste.
- Bucket Policy – definiowane na poziomie bucket’u, gdzie następuje potem dziedziczenie tych polityk przez obiekty. Bardziej przejrzyste i łatwiej zarządzalne.
Do zarządzania uprawnieniami do usługi zasobów służy też usługa Identity and Access Management. Tym razem jednak skupiamy się na S3 i opcjach w ramach tej usługi.
W drugiej części artykuły przyjrzymy się temu w jaki sposób ograniczyć możliwość wystawienia danych na świat (Public Access).
Cheers!
Zbuduje swoje bezpieczne środowisko AWS.